Information
Processing and Algorithmic Complexity
Pauli Salo
Cognitive Science
Department of Computer Science
University of Jyväskylä
ABSTRACT
Computational models of human cognition are often discussed
in terms of their relatively broad paradigms. For example, there exists much
literature concerning the pros and cons of connectionist versus classical
symbolic models. On the other hand, there is some evidence that even more
abstract properties might be relevant, as there are deficits, such as the
problem of ‘combinatorial explosion,’ that trouble both types of models, whether
connectionist or symbolic. It is argued in this paper that one such abstract,
yet relevant parameter is the ‘absolute information content’ of the model,
measured in terms of Kolmogorov complexity. This might be relevant since,
explicitly or implicitly, most computational paradigms are designed around the
idea of producing complex-looking structures from innovative simple principles,
such as recursion (classical models) or homogeneous networks (connectionism),
implying that they are extremely simple in terms of their Kolmogorov complexity.
It is argued that this strategy might not succeed. If these conclusions are
true, then the human mind is truly complex, lacking one crucial feature to which
many cognitive scientists have based all their wishes, namely, that the
complexity somehow ‘emerges’ from a right set of simple principles.
Keywords:
computational modelling, Kolmogorov complexity, connectionism, computationalism,
empiricism, reduction, emergence
1
Introduction
Computational models of human
cognition are often discussed in terms of the relatively broad paradigms. For
example, there exists much literature concerning the pros and cons of
connectionist versus classical symbolic models. Although the differences between
such paradigms are already rather abstract, it is precisely by virtue of this
abstractness that one can capture in a most effective way their differences,
limitations and capacities. On the other hand, there is some evidence that even
more abstract properties might be relevant, as there are deficits that haunt both types of models, whether
connectionist or symbolic. To mention one especially pertinent problem, both
kind of models tend to be either 1) applicable to a very narrow problem domain
or, 2) to be vastly complex computationally. Human cognitive processes, in
contrast, do not suffer from either in many domains. These problems are
certainly related to each other in a way that can be best described as the scaling problem: whenever a larger
problem domain is involved, computational models become too complex
computationally regardless of the more specific paradigm chosen.
The pressing question is of
course to determine how to scale the models and solve the scaling problem. How
we attempt to tackle this problem depends, in turn, on where we presuppose the
problem to be. One may assume that we just miss the correct heuristic algorithm,
correct set of parameters, or the correct network topology. When the correct set
of explicit axioms are in place, scalable cognitive processes emerge. For
example, using the correct learning algorithm with the correct network topology
would avoid the computational complexity of learning.
Another choice is to argue that
the limitations are not in the particular algorithms, but in some more abstract
level that concerns more or less all computational models. This stance is
characteristic of Dreyfus (1974) and Fodor (2000), for instance. I will argue in
this paper that the latter stance is indeed correct regarding the scaling
problem, and that the difficulties have to do with rather abstract properties of
all computational models. More particularly, I will argue that it is the absolute information content of those
models, not the specific designs or paradigms, that is insufficient and thereby
causes the scaling problem to occur.
In section 2, I will first show
how the rejection of the behavioristic stimulus-response psychology involved
arguments suggesting that there is substantial irregularity involved in
mental processing. In chapter 3, I will show how to translate and generalize
these observations to a more exact language with the help of Kolmogorov-complexity. In section 4, I
consider the consequences from the perspective of “information processing.”
Namely, if the stimulus states are truly random or
irregular in the sense of Kolmogorov complexity, then there cannot,
by the definition of “irregular,” exist any simple algorithmic solution for the
mapping of those states (say, acoustic features) into the corresponding mental
states (say, phonemes). On the other hand, it is easily seen that all
computational models currently explored, whether symbolic, connectionist or
dynamic, assume exactly the contrary: the information content of the model is
very low, apart from the misleading appearance. For instance, although a typical
neural network model appears to be a ‘complex’ web of nodes, this is very
misleading: its true information
content is very low, since all of the nodes are based on the same extremely
simple code describing the prototype of formal neuron. Similarly, in a typical
symbolic model, one uses recursion:
the same code over and over again with ingenious use of empty
memory.
I also argue that this might
provide an explanation for the fact that such models are computationally
complex, and that the problem domains in which human are engaged effectively
require much more ‘brute information’ as implicated in the current computational
models. Finally, it seems that it is not just the psychophysical functions which
are complex, but also many higher-level processes such as thinking: the case of chess expertise is
considered as an example.
2 Some empirical background: randomness in
psychophysics
In the
50’s, the collapse of the empiricist and behaviorist research programme paved
the way to the new mentalist inquiries. I will discuss some of the relevant
history of this process, at the risk of repeating of what is generally assumed
and basically well known. This provides one of the best-documented routes to the
phenomenon of ‘irregularity’ in cognitive processes, while it is irregularity or
even randomness in its various forms and implications that we will be concerned
throughout the paper.
American structuralists,
influenced by Bloomfield’s positivist conception of (the science of) language,
explored the possibility of capturing the notion of ‘phoneme,’ or any
‘linguistically relevant object,’ by using linguistic stimuli, phonetic
transcriptions, or even physical properties of utterances ¾ in fact, anything that was ‘directly observable,’ or was
thought to be so at that time. That undertaking is nontrivial: there is no
trivial mapping from sounds into the ‘phonological structure of the language.’
For instance, there is no reduction of phonemes into local physical properties
of sound. This is why taxonomists were structuralists as well: a phoneme for a
language L was assumed to depend on the properties of language L as a whole.[1]
As a corollary, it was hoped that
finding and defining linguistic elements from a corpus would be automated in
terms of a mechanical ‘discovery procedure.’ A discovery procedure is a
mechanical method which, given a corpus as input, gives a ‘linguistically
relevant’ taxonomy of elements and their relations for that corpus (or language)
as output. It was reasoned, on par with the pursuit of the discovery procedure,
that a child, when learning a language, must learn it from the stimulus
available, thus ‘discover its structure.’[2]
The discovery procedure and associated learning mechanism(s) represent an
‘empiricist learning algorithm’ so that, when demonstrated with some success, it
would show how the traditional ‘empiricist principles’ and doctrines could
actually work, at least in this case of human language(s). From the perspective
of computation, a discovery procedure is an algorithm targeted to find
regularities from the linguistic data and, based on such information, to
extrapolate the linguistics rules, principles and primitives in order to gain a
full mastery of the language.
However, it was eventually, though
also surprisingly, admitted that this project cannot succeed. In hindsight the
reason is easy to explain: the actual physical or acoustical realization of
‘linguistic elements’ result from numerous factors, so that it becomes
impossible to define them by relying upon their ‘observable properties.’ For
instance, the actual realization of a phoneme can be determined by at least the
following independent ingredients:
1.
independent phonological
rules
2.
rules of stress and
intonation
3.
rules of morphology and
syntax
4.
rules of articulatory
mechanisms and co-articulatory effects
5.
meanings (minimal
pairs)
To illustrate, consider such words
as sit-divinity and divine-car. In the latter
pair, the sound [A] corresponds to the letters a and i. Assuming that the orthography is
missing something, we conclude that divine is to be analysed as being close
to divAin and as being unrelated to
divinity expect for the initial
sounds, and related to cAr. Yet these
complications miss the fact that the ‘vowel shift’ is predictable based on
general rules, and is not idiosyncratic to divine-divinity (i.e. profane-profanity, serene-serenity,
explain-explanatory, various-variety,
Canada-Canadian).[3]
But assuming more abstract phonemes with independent phonological rules and
other factors (i-v above) this state of affairs becomes predictable. Linguists
were thus able to collapse the complexity of the theory at the cost of assuming
abstract phonemes and abstract principles
that regulate their realization in actual speech
sounds.
Given that the lower-level and
higher-level taxonomies are assumed as independent levels of linguistic
representations, two possibilities remain:
i.
we may stick with reductive definitions, leading us to a situation where
the theory of language use becomes
more and more complex due to the exceptions resulting from the mismatch between
the lower- and higher-level taxonomies and missed generalisations thereof; or
ii.
we may gain simplicity by jettisoning reductive definitions, relying upon
abstract, more or less ‘tentative elements’ that relate to actual sound only
indirectly, though by general rules.
Suppose
we adopt “Strategy i”. The theory is either poor in its explanatory power, or
leads to severe problems - and in the end also to anomalies - if applied to the
actual use of language. A more likely procedure would be to follow “Strategy
ii.” Pursuing (ii), linguists set up, first, a ‘tentative set of elements’ (i.e.
phonemes) and try to capture their relations to actual sounds, and to the more
abstract elements they are constituents of, by general rules and other
postulated interactions entering into the phenomenon we are studying (1-5
earlier).[4]
But then the physical properties ‘associated’ with the mental entities like
phonemes become more and more irregular and random: the cognitive states, as they clearly
mediate behaviour somehow, cannot be reduced to any regularity in the
stimulus, as was put by Howard Lasnik:
But what is a word? What is
an utterance? These notions are already quite abstract [...] The big leap is
what everyone takes for granted. It’s widely assumed that the big step is going
from sentences to transformation, but this in fact isn’t a significant step. The
big step is going from “noise” [irregularity] to “word.” (Lasnik, 2000, p.
3.)
There are
obscuring random factors that blur the connection between what the subject hears
and what appears in his or her ears. Yet these problems are entirely general,
spanning through the domain of what we may pre-theoretically speak of as ‘the
mental,’ or which falls naturally under the title of ‘mentalistic inquiries.’
Julian Hochberg was one of those who tried to find psychophysical laws to
connect percepts with physical invariances in the environment, but he abandoned
the project because
(1) […] we don’t have a
single physical dimension of stimulation by which to define the stimulus
configuration to which a subject is responding, or by which we can decide what
it is that two different patterns, which both produce the same form percepts,
have in common [and] (2) because the subject can perceive very different form in
response to the same physical stimulus, and which form he perceives critically
determines the other answers he gives to questions about shape, motion, size,
depth, and so on. (Hochberg, 1968, pp. 312-313.)
That is,
the science of what is perceived and how the organism comes to behave in
response to such stimuli is not the
science of the physical conditions imposed upon his or her senses. Rather, as
these lower and higher taxonomies of properties cross-classify each other, we
are forced to rely upon tentative theoretical constructs, such as ‘percepts,’
and leave their exact characterization for a science-to-come to
explore.
We may even say that physical,
directly observable sensory states are, because they are irregular, more or less
random vis-à-vis the ‘percepts,’ as
was suggestedby Zenon Pylyshyn: ‘if
we attempt to describe human behaviour in terms of physical properties of the
environment, we soon come to the conclusion that, except for tripping, falling,
sinking, bouncing of walls, and certain autonomic reflexes, human behaviour is
essentially random’ (Pylyshyn, 1984, p. 12). According to Fodor, it is because
required physical invariants are absent in the impoverished sensory organs that
”perception cannot, in general, be thought of as the categorization of physical
invariants, however abstractly such invariance may be described” (Fodor, 1975,
p. 48, footnote 15). The taxonomies based on sensory stimulations are not
necessary, not even sufficient, to allow useful generalizations about behavior
and actual language use, though here we must remember that the speaker/hearer
must still be able to somehow correlate ‘random noise’ to linguistic/mentalistic
categories– the notorious problem to which I return presently.
3. Complexity, empiricism and
randomness
In this
section I want to consider the phenomenon of ‘randomness’ and its relation to
reduction more closely. My reasons for wanting to do this will become clear
later; suffice it at this point to note that the issue of randomness and
complexity is directly relevant to the issue of computation and, in a similar vein, to
issues of ‘information processing.’ Furthermore, the issue of ‘complexity’ has
certainly played a role in shaping the discussion of the very nature of social
scientific laws (e.g. Clark, 1998, McIntyre, 1993, Sambrook & Whiten, 1997,
Rescher, 1988), so any conceptual clarification on the matter could be
potentially helpful.
Suppose that we have two kinds of
information readily available: pairs consisting of physical sensory properties
(Q) and the corresponding ‘perceptual classification’ of that physical
stimulus-in-a-context (P). If the above observations (§2) are anywhere near the
truth, it must be the case that these pairs do not possess significant
‘regularity.’ For example, an arbitrary collection of noises can correspond to
the perception of phoneme /m/. Borrowing some philosophical jargon, the
higher-level property p1 corresponds to a ‘disjunctive property’
q1 Ú q2 Ú . . . (see Fodor, 1974). Looking at the matter from a slightly different
perspective, suppose we fix p1 and collect various sensory stimuli
that appear to be as paired with p1. We expect them to contain no
physical invariance(s). The high-level properties are not ‘projectible’ to the
lower-level ones, or they do not have a ‘model’ at the lower level (in the sense
of being logically constructible at the lower level).
Let us consider more carefully the
notion of ‘randomness’ or ‘lack of invariances’ we are supposed to be
observing. What does it mean if
some object lacks regularity or involves ‘disjunctive properties’? There exists
a long tradition in hunting down the correct properties of this notion, omitted
here (but see Li & Vitányi, 1997). The most satisfactory notion of
randomness, and most important for the present purposes, can be formulated with
the help of Kolmogorov complexity.
Kolmogorov complexity measures the ‘absolute information content’ of a finite
object so that a ‘complex’ or ‘random’ object is one which is its own shortest description
and thus cannot be ‘compressed’ based on any regularity.
Suppose that in describing
sequences of strings of 0s and 1s, or whatever alphabet we choose to use, we use
computers and their programs. Computers plus their programming languages,
henceforth called ‘specification methods,’ are understood as recursive functions
f1, . . . from programs p into outputs x. Let | × | measure, in bits, the length of those programs. Fixing
f, we may follow the above idea and
define the complexity of x, Cf(x), as follows:
Cf(x) = min{ | p | : f(p) = x }.
Thus, we
search for the minimal program that can produce x. Intuitively, if p is much shorter than x, we say that there is a compression of x in terms of p. It is hoped that this measure will
screen out the regularities in x and,
if there is no such compression, we may call x ‘random’ or ‘irregular’. The idea is
intuitively appealing, since the existence of a much shorter computer program
for producing x captures the rules
and regularities in x that ‘random’
entities, perhaps by definition, must lack entirely. Randomness, in our sense,
is then a property of data, not of
process (of ‘chance’). Thus, string
is not
‘random,’ since there exists a very short computer program that prints it,
namely:
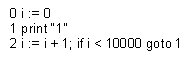
This
program is a ‘compression’ of the string, capturing its regularities. The same
is true of the decimals of p, which are not random by the proposed test: they can be
computed by using small computer program (although p is random by many other tests).
Returning to the formal properties
of this notion, trying to shape the notion of ‘randomness’ along these lines, it
appears that there might be other specification methods, computers and computer
languages, that can compress even x
further. We do not want randomness to be relative to a particular specification
method, yet it is meaningful to ask if the above string would be more random
with respect to LISP than FORTRAND. In other words, is there a minimal element
for C(x), free of the choice of the
specification method?
It is easy to develop a measure
that takes these choices into account. Suppose that we have specification
methods f1, . . . fn available, one being LISP interpreter,
the other being FORTRAND interpreter, and so on. We may choose which programming
language to prefer. Then we can develop a new specification method, g, that makes the choice and computes
string x. The input of g consists of information concerning
method f, clearly a constant, c (say, log n), plus the program, p. We then obtain a new specification
method with the property that for any x and f, Cf(x) £ Cg(x) + c. That is, the complexity method g outputs for any string exceed those
given by any of the fs only by
constant c, an asymptotically
vanishing price to pay for the fact that we can use several specification
methods in seeking regularities in the data. Seen from a more intuitive point of
view, we establish a ‘compromise’ between finding the absolute minimal
specification method plus the specification of that methods itself, seeking the
alternative that is the least expensive with respect to this measure. No other
method in our initial stock can improve this result infinitely often.
We may go further and imagine a
situation in which any computational
specification technique, that is, any possible (imaginable, constructible)
computing language, is used. There are an infinite number of such techniques, as
there is an infinite number of recursive functions. But suppose that, despite
this obstacle, we choose to develop a specification method, comparable to g above, that is capable of making the
choice between them. For this purpose we can use the universal Turing machine f0
(i.e. a function f0 such
that for any n and p, f0(n, p) = fn(p)). Thus, with the help of this new
powerful specification method, we can define a new notion of complexity,
C0(x) = min{| p |: f0(n, p) = x},
obtaining, analogously to the previous
case,
C0(x) £ Cn(x) + cn,
where c can be set to 2| n | + 1, depending only upon fn. This extra cost is due to
the coding of the specification method, depending only on the method chosen.
This is the invariance theorem of
Kolmogorov complexity, its mathematical cornerstone, established independently
during the 60’s by R. Solomonoff (1964), A. N. Kolmogorov (1965), and G. Chaitin (1969). This theorem establishes the fact that our
intuitive idea of measuring complexity in terms of shortest descriptions has
just the desirable mathematical properties we expect it to have: complexity is
invariant with respect of the specification method used, as long as the
specification method is computable.
I will not discuss further here
the interesting mathematical properties of this measure. Suffice it to say that
it is closely related, in an interesting way, to many other mathematical
notions, such as Shannon’s information theory, proof-theory, computability
theory, machine learning, probability theory, and, indeed, many others (see Li
& Vitányi, 1997). Moreover, it is also related to some fundamental physical
measures and hence subject to explanations in physics, such as entropy and
information (see Zurek, 1990). Some authors have also claimed that it is
relevant to human cognition (more below). But in any case, I postulate that,
concerning the notion of randomness, Kolmogorov complexity is “about as
fundamental and objective as any criterion can be” (Rissanen, 1990, p.
118).
Let us return to cognitive science
and the case of unsuccessful reduction and associated, abandoned empiricism
discussed earlier (§2). What is established, if these empirical arguments are
true, seems to be related to the complexity-property captured by
K(olmogorov)-complexity above, or to some relevant variant of it. It was argued
that there are no invariances in the set of stimuli correlating with, or
defining, a given mentalistic state. Assume that the notion of ‘invariance’ is
restricted to computable invariances (which is entirely reasonable); then the
lack of such invariances can be identified by the fact that there is no computer
program, in the sense given above, which can compress the set of stimuli sampled
together with the ‘mental state,’ or whatever the abstract property we target in
our explanations is. For this reason the set can be said to be necessarily
‘disjunctive’: each member must be stated as such, in the absence of any common
(defining) invariance. That is, Kolmogorov complexity seems to capture exactly
an important aspect of what happened when the stimulus-response psychology
collapsed: certain kinds of complexity or irregularity prevented that program
from succeeding.
Consider this assumption from the
perspective of ‘information processing.’ We assumed that the stimuli are
characterised by its K-complexity vis-à-vis the ‘mental state’ it is
‘correlated’ with, the notion of ‘mental state’ taken still in a pre-theoretical
sense but understood as being, for example, a perceptual hypothesis concerning
the world beyond the sensory organs. The relevant set of stimuli being K-complex
means, by definition, that a simple
algorithm to make the required computations and correlations does not exist.
It might even be that ‘information
processing’ is itself a somewhat unfortunate term here, connoting to the idea,
explicitly argued by the behaviorists and Gibson, and implicitly by many others,
that the sensory channels could end up with rational hypothesis by literally
manipulating the information present in the senses, whereas a truer picture
should take the sensory channels to be essentially sources of disturbing noise
that the system must somehow deal with in inferring what’s behind one’s eyes or ears. These two
perspectives on the functioning of the senses might imply, though they are
metaphorical, radically different strategies for a more rigorous empirical
research.
Simplifying, this conclusion is
inescapable in the following conceptual sense. Defining the autonomy of the
mental as a lack of sensory invariance sounds to me like it is being defined as
a lack of computational invariance that could be found from the stimulus
properties. The latter is just a more formal statement of what is said
empirically in the former. But then it all comes down to whether there is an algorithmic solution for
‘perceptual classification,’ since, if there is, we can withdraw to behaviorism;
yet if this is not going to happen, there cannot exist such an algorithm. In other
words, on a certain abstract but arguably relevant level of analysis, all
computationalists are still behaviorists: it is their simple program code that
describes a putative connection between a simple stimulus regularity and a response. Skinner would have called this
a S-R –law (Skinner, 1953, pp. 34-35).
Some authors have explicitly
denied the present thesis, namely, that the human mind is, in an important
sense, confronted with complexity, noise, or irregularity, by proposing that one
of the fundamental cognitive principles would be to search for simplicity in terms of K-complexity
(Chater, 1996, 1999). Chater argues that the world around us is ‘immensely
complex’ yet, oddly enough, ‘highly patterned,’ whereas the ability to ‘find
such patterns in the world is [...] of central importance throughout cognition’
(Chater, 1999, p. 273). Such ‘patterns are found by following a fundamental
principle: Choose the pattern that provides the simplest explanation of the available
data.’ Chater then captures the relevant notion of simplicity in terms of
K-complexity, arriving at virtually the opposite thesis proposed here. But the
matter is naturally empirical. We have seen some evidence from the properties of
language and the rejection of behaviorism (§2) that a cognitive agent could not
succeed in learning a language by following the principle(s) proposed by Chater,
and that the matter could be rather the opposite. It is in fact the standard
argument against empiricism and behaviorism to show that, were a child to choose
the simplest hypothesis, he or she would fail in a way that is against the
empirical facts (see Crain & Lillo-Martin, 1999).
On the other hand, those who have
assumed the autonomy thesis introduced in section 2, together with the
associated rejection of empiricism, have of course been referring to
‘complexity’ in capturing the empirical consequences of the issue. It was
suggested much earlier already against behaviorism that ‘we may now draw the
conclusion that the causation of behavior is immensely more complex than was assumed
in the generalizations of the past,’ since a ‘number of internal and external
factors act upon complex central
nervous structures’ (Tinbergen, 1951, p. 74, my emphasis). Furthermore, ‘the
program [of behaviorism] seems increasingly hopeless as empirical research
reveals how complex the mental
structures of organisms, and the interactions of such structures, really are’
(Fodor, 1975, p. 52, my emphasis).
In the present case I argue that the ‘complexity’ is K-complexity, thus
meaning complexity in an information theoretical sense.[5]
Finally, consider the important
insight concerning complexity in social sciences provided by McIntyre (1993)
that ‘one cannot say that at any
level the phenomena are too complex for us to find laws, for complexity just is a function of the level of
inquiry that we are using.’ The claim is that whether a rational inquiry is
blocked by complexity depends upon the chosen level of description. I am not
denying that claim. K-complexity is
applied to a putative level of description: the behaviorist and taxonomist
descriptions on the other hand, the mentalist descriptions on the other.
Complexity is a consequence of the wrong
choice; the semantics of making and constructing one particular choice and
teasing out the formal structure based on the preferred choice is another
matter. I also agree with McIntyre in that complexity does not prevent one from
finding simplicity, given that the level of description is correct: modern mentalism in
linguistics seems to support exactly this
claim.
4 Kolmogorov complexity and computational
complexity
If what I
have argued so far is true, then there are some consequences worth of taking a
closer look. Looking at most computational models entertained in cognitive
science, whether connectionist models, dynamical models, algorithms for pattern
recognition, and so on, they seem to be ‘K-simple algorithms’ that try to induce
(or ‘adapt to’ or ‘self-organize to’) invariances in their ‘sample space.’
Consider, for example, a typical associationist model. The model consists of a
number of nodes, connected to each other via connections that allow information
to ‘flow’ in the network. This flow is controlled by specific weights, attached
to the connections, plus various properties of the nodes themselves. I spare the
reader the details, since they are widely known. A typical network nevertheless
looks as follows:
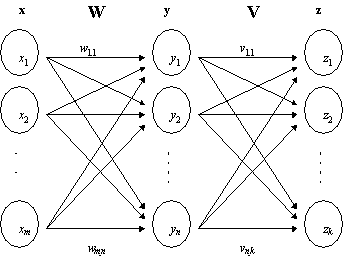
Figure 1. A typical connectionist
model
Although
the entire network looks like a complex entity, it is extremely simple in terms
of its K-complexity, hiding its simplicity (and triviality) within its complex
but misleading appearance. The information that spans the whole network consists
of two parts: the extremely simple code specifying the computations in the
formal neuron, the node (or better, each node), the other to copy this node
everywhere, plus setting up the initial pseudo-random (that is, K-simple),
connections between the nodes. In fact, this seems to be the very idea, and
presumably also one part of the attraction of such models (and maybe empiricist
models in general): hooking up a complex-looking system with the lowest possible
amount of information. Yet if mentality, understood here as opposed to
stimulus-response behaviorism, consists, in part, of high information content,
or disparity between the ‘data’ and ‘perceptual hypotheses,’ these models are
indeed not to be expected to do, or explain, much. Even if they look like
complex systems, they capture only simple invariances.
This is not to be intended as a
critique of connectionism, specifically. What are called ‘symbolic models’ or
‘Classical models,’ at least what comes to those involved in modelling human
performance, as opposed to competence (see below), do not often fare better in
this respect, since they just embody other means to save information in order to
attain K-simplicity. Recursion is one favorite and ingenious procedure. By using
recursion with memory for bookkeeping one can do a lot by writing a simple code
which, in an admittedly ingenious manner, is able to ‘use itself’ to define
further computations and properties.
It is also possible, in principle,
to provide the required information for a model in each paradigm without
rejecting the whole approach. For instance, one could code information to the
weights between the nodes in a connectionist network, or to the activation
values (if they are real numbers), or use a large databank in the case of a
symbolic model. But that never happens, the present point being that is should
happen.
For, interestingly, both models,
‘symbolic’ and ‘connectionist,’ are usually hopeless from a psychological point
of view, a fact that has been known for long, but which has not, I believe,
received enough attention in print (but see, for example, Fodor, 2000). These models are always computationally complex. Being computationally complex means
‘computationally deep’: to check whether some property or invariance holds for a
item in the data set, one must compute a lot, often exhaustively in the worst
case. Typically the increase of computation is an exponential function of the
increase of the size of the data, soon rendering the actual process hopeless, as
was put by Dennett:
As we ascend the scale of
complexity from simple thermostat, through sophisticated robot, to human being,
we discover that our efforts to design systems with the requisite behaviour
increasingly run foul of the problem of combinatorial explosion. Increasing some
parameter by, say, ten percent¾ten percent more inputs or more degrees of freedom in the
behaviour to be controlled or more words to be recognized or
whatever¾tends to increase the internal complexity of the system
being designed by order of magnitude. Things get out of hand very fast and, for
instance, can lead to computer programs that will swamp the largest, fastest
machines. Now somehow the brain has solved the problem of combinatorial
explosion (Dennett, 1997, p. 77).
I view it
as an interesting hypothesis to speculate whether the drastic failure of
computational models in terms of their computational complexity and the scaling
problem is actually a consequence of their underlying empiricist philosophy of
getting complex-looking models ‘emerging’ out of only very few bits of
information? Consider the situation these models are required to handle as it is
seen through K-complexity: a simple model is required to do something that, by
its nature, requires a lot of information and irreducible complexity. What are
the possible consequences? Such models are predestined to fail, perhaps exactly
so that the lack of informational complexity is traded into a overflow of
computational complexity.[6]
Let us consider these arguments
from the perspective of well-defined problem domain, that of chess. Chess is a computationally complex game (Stockmeyer & Chandra, 1979): computing the ‘next good’ move consumes
considerable amounts of computational resources. Suppose that we take the
stimuli to consist of pairs áq, pñ of board positions in a chess game. We take the response
to consist of a judgement of whether p would represent a good and possible move,
with respect to initial position q. Now, let us suppose that this computational
ability is studied by Martian scientists who have no knowledge of chess. All
they have at their disposal is a sample of good moves, and hence a sample of the
extension of the concept of ‘good move.’ They ask whether there exists a simple
invariance, formulated by relying upon the stimulus pairs áq, pñi, that defines the
extension of the concept ‘good move.’ If they find an invariance, it is possible
to reason that it is this property to
which the players are ‘responding.’ If the Martians are clever, they can indeed
find an extremely simple (in terms of K-complexity) invariance behind all the
moves, namely, the one that performs a more or less exhaustive search within the
limits of the rules of chess, looking either to win, or to find ‘good positions’
(comparable to any chess program with at least moderate skill). The invariance
in question is, although very parsimonious, ‘computationally deep,’ requiring
computational resources in order to be ‘defined’ over the sample of good moves;
or to borrow a phrase from Luc Longpré, ‘the non-randomness is so intricately
buried that any space or time bounded process would fail to detect it’ (Longpré,
1992, p. 69).
Having found such a deep
invariance, Martians would wonder how the human mind could respond so rapidly,
given that the property it is responding to is computationally deep. In fact,
they would find that humans entertain only a few hypotheses. Furthermore, it would
soon become apparent that, when given certain ‘untypical’ chess boards, the
concept of ‘good move’ entertained by human subjects would not correspond with
the one defined by the exhaustive search methods. (As is well
known, human performance would cease in such conditions, while the
computational method could maintain its level of play
easily.)
From the perspective of Kolmogorov
complexity: when the amount of hypotheses (computations) that are allowed to be
considered in the game is made realistic from a psychological point of view
(say, restricted to 50 as opposed to the hundreds of millions computed by
computers), the set of ‘good moves’ will, with near certainty, assuming only
that the nontrivial character of chess is maintained in the instance that we are
actually playing on, look more and more random (see Li & Vitányi, 1990, §7). In other words, since the invariance is
computationally deep, players cannot detect it if they do not compute; and since
they do not compute, they must be responding to what would appear more or less
to be ‘noise,’ that is, a good deal of randomness in terms of K-complexity. It
follows that computationally shallow chess cannot be played by using
‘computational tricks.’ That is, there are no ingenious ‘heuristic models’ to explain how the players select the
relevant move, considering just a few alternatives – and no scientific interest
whatsoever in finding one, contrary to the prevailing view among those partaking
in computational theorising (cf. Newell, Shaw, & Simon, 1958, Newell
& Simon, 1963, 1972). Players are responding to mere noise insofar
as their computations are shallow, at most mimicking a computationally deep
invariance on a selected array of positions, but not in others. Indeed,
empirical evidence to this claim can be found by considering the construction of
actual chess playing programs, which, when they succeed in beating human
players, either compute enormous amount of positions, require extensive database
of brute information, or indeed just both.[7]
Summarizing, it had seem impossible to
implement ‘rational inference,’ whether perceptual or a higher level,
characteristic of human intelligence, using computational techniques. The
problem is that, in fixing beliefs based on an agent’s epistemological
commitments, rationality seems to require a considerable amount of
holism-cum-context-sensitivity: the processes seems to be sensitive to the whole
background of beliefs and desires, whereas, as is well-known, ‘[c]lassical
architectures know of no reliable way to recognize such properties short of
exhaustive searchers of the background of epistemic commitments’ (Fodor, 2000,
p. 38). That is, rationality is purchased by lots of information (background
knowledge) plus deep computation in exploring it.
In his latest book, Fodor (2000)
argues that the problem of abductive inference renders the whole computational theory of the mind
suspect, at least as far as the non-modular components of human cognition are
concerned. He writes that the problem originates in the locality of
computational processes versus the context-sensitivity of the corresponding
cognitive processes. The ‘local formal properties’ of a thought – its so-called
‘logical form’ – does not suffice to determine its causal-cum-inferential role
in the system. That is the problem of ‘locality’; in fact, presumably the same
problem that we observed in the case of chess, viz. that the property of ‘good
move’ cannot be defined without extensive use of computations on the formal
properties of a chess board. We may say that the property of being a good move
is ‘context-sensitive’ because it depends not on the local properties of the
board position, but on the location of this board position in the space of
possible games and their outcomes. As a consequence, we need to explore this
space, the ‘context’ of a single board. As Fodor correctly notes, this, in
general, characterizes practically any
routine inference in our normal environment: what we do infer, and ought to
infer, depends not on the ‘logical form’ of the single thought, but rather on
its place in the vast web of our epistemological commitments as a whole. The
notion ‘logical form of thought’ is thus simply the wrong kind of idealisation
in that case.
5 Conclusions
Empirical
evidence has made the empiricist picture of the mind less and less attractive
over the last 50 years or so, being replaced with a more rationalist one that
emphasises the role of innate structure instead of environmentally induced
complexity. I have argued that one important aspect of this difference might
come to abstract Kolmogorov complexity, which, as it is based on exact
mathematical formulation and instant generalizability, is applied to all
computational modelling, hopefully explaining why such models have failed
regardless of the paradigm used, and will fail in the future unless the hidden
empiricist premises are rejected.
If these speculations are not
completely off the mark, then the human mind is truly complex, lacking one
crucial feature to which many cognitive scientists have based all their wishes,
namely, that the complexity somehow ‘emerges’ from a right set of simple
principles. How and why physical laws kick off a process that could generate
information and complexity remains to be seen (see Chaitin, 1979, Bennett,
1988a, b, McShea, 1991, Sambrook, & Whiten, 1997, Zurek, 1990, among
others). Given the fact that DNA in our genes does not seem to involve that much
information at all, one would wonder if there is something in the nature, in the
ontogeny of an human being, that produces true information, and whether there is
something that can crystallize it to use (Griffiths & Gray, 1994, Oyama,
2000)?
Almost miraculously, there are areas of interest, most of them the modular aspects of cognition, where general and elegant principles have been found within a ‘single level of analysis’ despite the apparent complexity between levels. According to my standards of scientific explanation, this is especially true in the case of knowledge (competence), but not so in the use of that knowledge (performance). Such abstract knowledge of chess rules would be easily extracted from observing the play, but it is the effective use of that knowledge which remains a mystery.
References
Chaitin, G. J. 1969: On the length of programs for
computing finite binary sequences. Journal of Association of Computer Machinery,
13, 547-569.
Chater, N. 1996:
Reconciling Simplicity and Likelihood Principles in Perceptual Organization.
Psychological Review, 103(3), 566-581.
Chater, N. 1999: The
Search for Simplicity: A Fundamental Cognitive Principle. The Quaterly Journal
of Experimental Psychology, 52A(2), 273-302.
Chomsky, N. 1981: Reply to Putnam. In N. Block (Ed.),
Readings in Philosophy of Psychology . Cambridge, MA.: Harvard University
Press.
Chomsky, N. 2000: New Horizons in the Study of Language and
Mind . Cambridge: Cambridge University Press.
Chomsky, N., & Halle, M. 1968: The Sound Pattern of
English. New York : Harper & Row.
Churchland, P. 1981: Eliminative Materialism and
Propositional Attitudes. Journal of Philosophy, 78(2),
67-90.
Clark, A. 1998:
Twisted tales: Causal complexity and cognitive scientific explanation. Minds and
Machines, 8(1), 79-99.
Cosmides, L., & Tooby, J. 1997: The Modular Nature of
Human Intelligence. In A. Scheibel & J. W. Schopf (Eds.), The Origin and
Evolution of Intelligence (pp. 71-101). Sudbury, MA: Jones and
Bartlett.
Cowie, F. 1999: What's Within? . New York: Oxford
University Press.
Crain, S., &
Lillo-Martin, D. (1999). An Introduction
to Linguistic Theory and Language Acquisition . London: Blackwell
Publishers.
Dennett, D. C. (1997).
True Believers: The Intentional Strategy and
Why It Works. In J. Haugeland (Ed.), Mind
Design . Cambridge, MA.: MIT Press.
Fodor, J. A. 1974: Special sciences (or: the disunity of
science as a working hypothesis). Synthese, 28, 97-115.
Fodor, J. A. 1975: The language of thought. New York:
Crowell.
Fodor, J. A. 1987: Modules, Frames, Fridgeons, Sleeping
Dogs, and the Music of the Spheres. In Z. W. Pylyshyn (Ed.), The Robot's Dilemma
(pp. 139-149). New Jersey: Ablex Publishing.
Fodor, J. A. 1989: Why Should the Mind be Modular? In a.
George (Ed.), Reflections on Chomsky (pp. 1-22). Oxford: Basil
Blackwell.
Fodor, J. A. 2000: The mind doesn't work that way. The
scope and limits of computational psychology . Cambridge, MA.: MIT
Press.
Griffiths, P. E., & Gray, R. D.
1994: Developmental systems and evolutionary explanation. Journal of Philosophy,
91, 277-304.
Harris, Z. 1957: Methods in Structural Linguistics .
Chicago: Chicago University Press.
Harris, Z. S. 1951: Structural Linguistics . Chicago:
Univeristy of Chicago Press.
Harris, Z. S. 1955: From phoneme to morpheme. Language, 31,
190-222.
Hochberg, J. 1968: In the Mind's Eye. In R. N. Haber (Ed.),
Contemporary Theory and Research in Visual Perception . New York: Holt, Rinehart
& Winston.
Kolmogorov, A. N.
1965: Three approaches to the quantitative
definition of information. Problems of Information Transmission, 1(1),
1-7.
Li, M., & Vitányi,
P. M. B. 1990: Kolmogorov Complexity and Its
Applications. In J. v. Leeuwen (Ed.), Handbook of Theoretical Computer Science
(vol. A) (pp. 188-254).
Li, M., & Vitányi,
P. (1997). Introduction to Kolmogorov
complexity and ts applications . New York: Springer-Verlag.
Longpré, L. 1992: Resource bounded Kolmogorov Complexity
and Statistical Tests. In O. Watanabe (Ed.), Kolmogorov Complexity and
Computational Complexity (pp. 66-84). Berlin:
Springer-Verlag.
McIntyre, L. C. 1993:
Complexity and social scientific laws. Synthese, 97, 209-227.
McShea, D. W. 1991: Complexity and
evolution: What everybody knows. Biology and Philosophy, 6, 303-324.
Newell, A., Shaw, J. C., & Simon, H. 1958: Chess
playing programs and the problem of complexity. IBM Journal of Research and
Development, 2, 320-335.
Newell, A., & Simon, H. A. 1963: GPS: A program that
simulates human thought. In E. A. Feigenbaum & J. Feldman (Eds.), Computers
and thought (pp. 279-293). New York: McGraw-Hill.
Newell, A., & Simon, H. A. 1972: Human problem solving
. Englewood Cliffs, NJ.: Prentice-Hall.
Orponen, P., Ko, K.-I., Schöning, U., & Watanabe, O.
1994: Instance Complexity. Journal of the Association for Computing Machinery,
41(1), 96-121.
Oyama, S. 2000: The ontogeny of
information: Developmental systems and evolution. Durham, NC: Duke University
Press.
Putnam, H. 1971: The 'Innateness Hypothesis' and
Explanatory Models in Linguistics. In J. Searle (Ed.), The Philosophy of
Language . London: Oxford University Press.
Pylyshyn, Z. W. 1984:
Computation and cognition: Toward a foundation
for cognitive science . Cambridge: The MIT Press.
Remez, R. E., Rubin, P. E., Pisoni, D. B., & Carrell,
T. D. 1981: Speech perception without traditional speech cues. Science, 212,
170-176.
Rescher, N. 1998:
Complexity: A Philosophical Overview . London: Transaction
Publishers.
Rissanen, J. (1990).
Complexity of Models. In Zurek (1990), pp. 117-125.
Sambrook, T., &
Whiten, A. 1997: On the Nature of Complexity in Cognitive and Behavioural
Science. Theory & Psychology, 7(2), 191-213.
Skinner, B. F. (1953). Science and Human Behavior. New York:
Macmillan.
Solomonoff, R. J. 1964: A formal theory of inductive
inference, part 1, part 2. Information and Control, 7, 1-22,
224-254.
Stockmeyer, L. J., & Chandra, A. K. 1979: Provably
difficult combinatorial games. SIAM Journal of Computing, 8,
151-174.
Tinbergen, N. 1951: The Study of Instinct . Toronto: Oxford
University Press.
Watanabe, O. 1992: Kolmogorov complexity and computational
complexity. Berlin: Springer-Verlag.
Zurek, W. H. 1990 (Ed.): Complexity, entropy and the physics of
information. Redwood, CA.: Addison-Wesley.